










<a href="https://www.macstories.net/feed/" rel="nofollow">https://www.macstories.net/feed/</a>


9 public comments

Hulk’s guitar isn’t plugged in but fuckit, we’re not here to listen to him play rythym
Bend, Oregon

“We hypothesize that migraine should be considered a neural disorder of brain function, in which alterations in aminergic networks integrating the limbic system with the sensory and homeostatic systems occur early and persist after headache resolution and perhaps interictally. The associations with some of these other disorders may allude to the inherent sensory sensitivity of the migraine brain and shared neurobiology and neurotransmitter systems rather than true co-morbidity.”
Epiphyte City
Modern Love Season 2: An Interview with Andrew Rannells
https://www.nytimes.com/2021/08/13/style/modern-love-episode-7-andrew-rannells.html
https://www.nytimes.com/2021/08/13/style/modern-love-episode-7-andrew-rannells.html
Watch
Wigan
Google Adds RSS to Chrome for Mobile https://www.phonescoop.com/articles/article.php?a=22642
Long live Google Reader??
Long live Google Reader??
this. If a in hi p
Descarga aquí la app de MARCA.com.
@elmundoes
https://itunes.apple.com/es/app/el-mundo-diario-online/id324300162?mt=8
@elmundoes
https://itunes.apple.com/es/app/el-mundo-diario-online/id324300162?mt=8
January 7, 2019 at 11:25 PM by Dr. Drang
This morning, Casey Liss tweeted out a complaint about a typical Siri stupidity:
Silver lining of Apple’s focus on services: maybe Siri will actually… work? 🤨
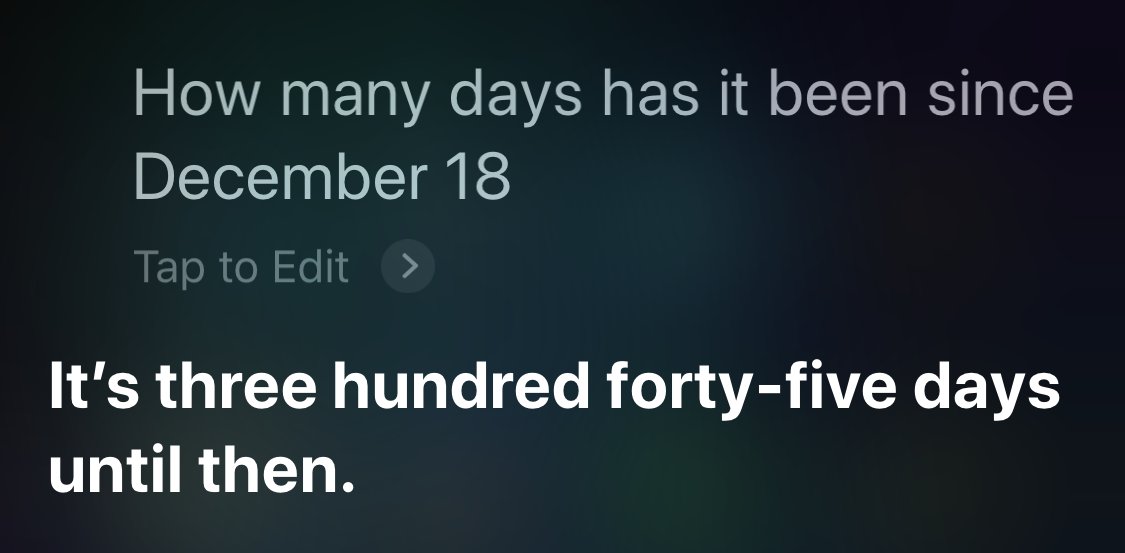
This was a bit of a shock to me, not because I thought Siri was smarter than this, but because I had been collecting similar Siri screenshots concerning dates and times for a few days and was planning to write a post about it. This post.
Before I get any further, let me tell you that some of what I’m going to say here was already covered by David Sparks in this post from almost six years ago. This was just a year and a half after the “beta” introduction of Siri with the iPhone 4S, and David was pleased with what Siri could do. I like a lot of what Siri can do with dates, too, but there are still some frustrating blind spots and inconsistencies. In fact, with one of David’s examples, Siri isn’t as convenient as it was six years ago.
Context has always been one of Siri’s weaknesses, and that’s where it failed Casey. Any normal human being would understand immediately that a question asked in January about days since a day in December is talking about the December of the previous year. But Siri ignores (or doesn’t understand) the word “since” and calculates the days until the next December 18.
If you take care to give Siri the full date, it gives the right answer:1
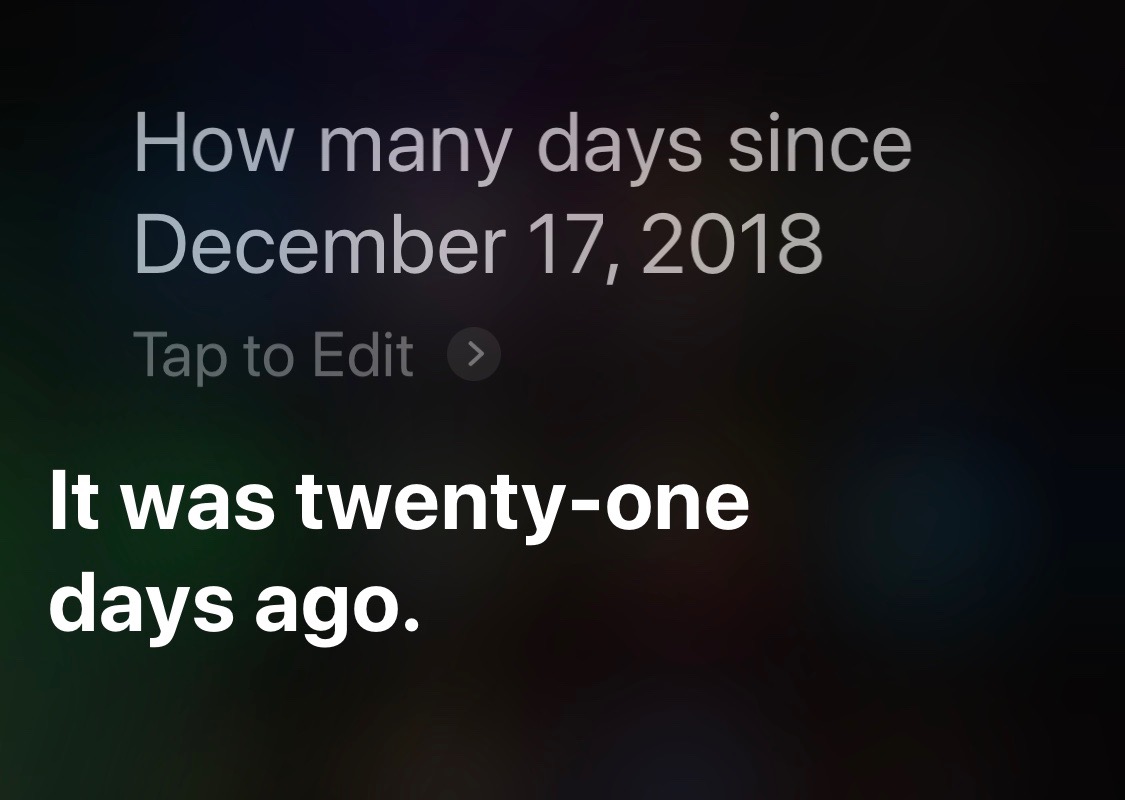
You might think—which is to say, I originally thought—that Siri defaults to the current year when the year isn’t given in the question. You would be wrong. Take a look at this, a question I asked today:
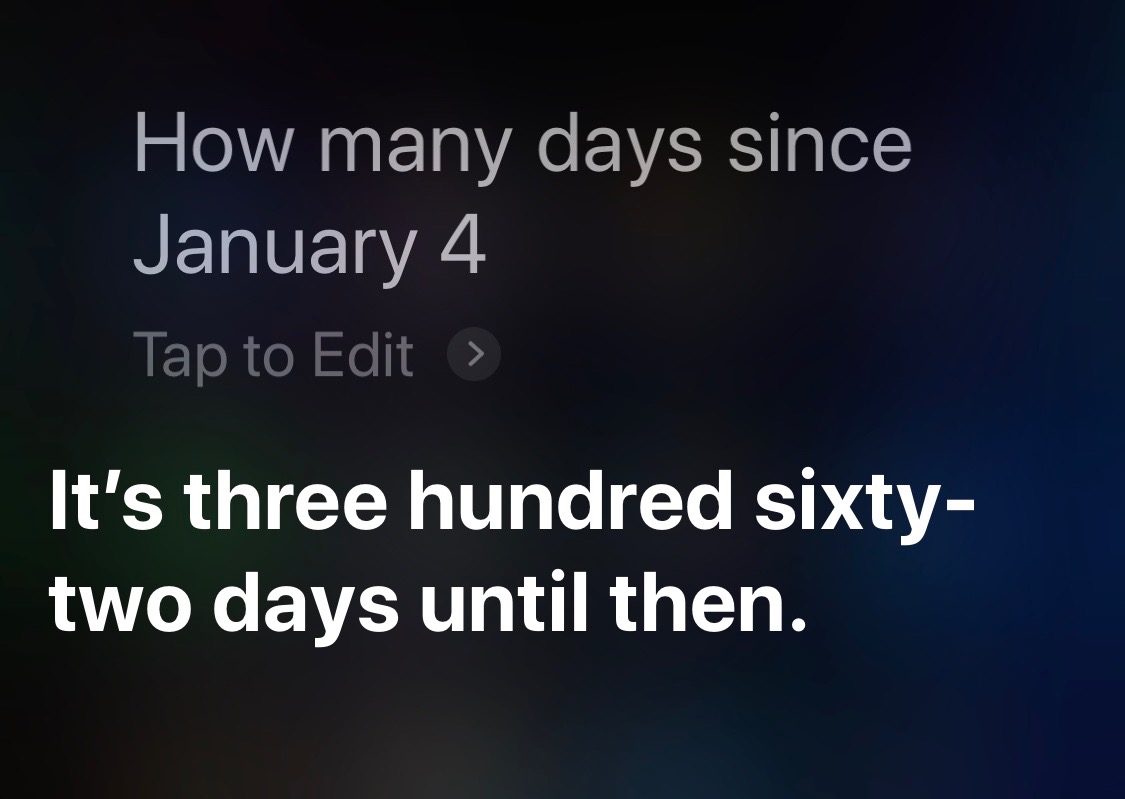
Apple would argue that Siri is forward-looking technology.
One bit of date math on which Siri has never failed me is getting the day of the week for a given date. I use this quite often at work, especially when the date in question is years in the past and flipping backward through a calendar app would take too long.
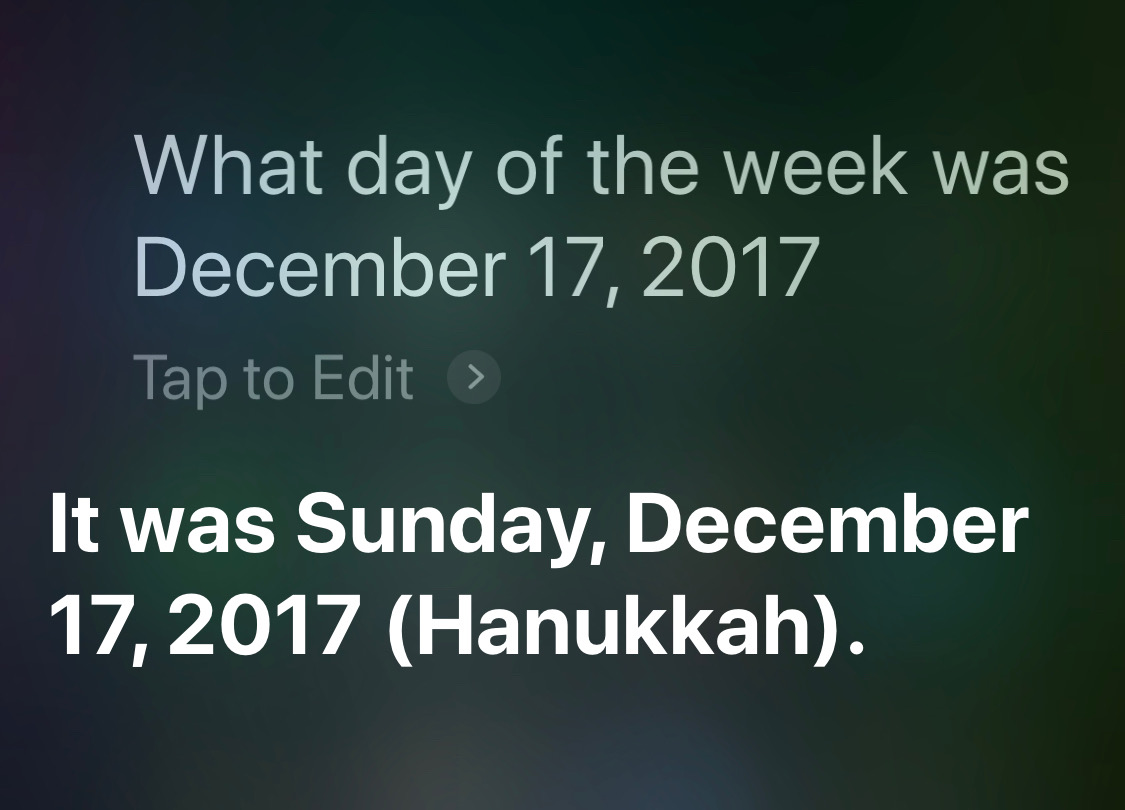
For dates well in the past, I would never think of not including the date, but for dates later in the current year, I would. Siri handles them well:
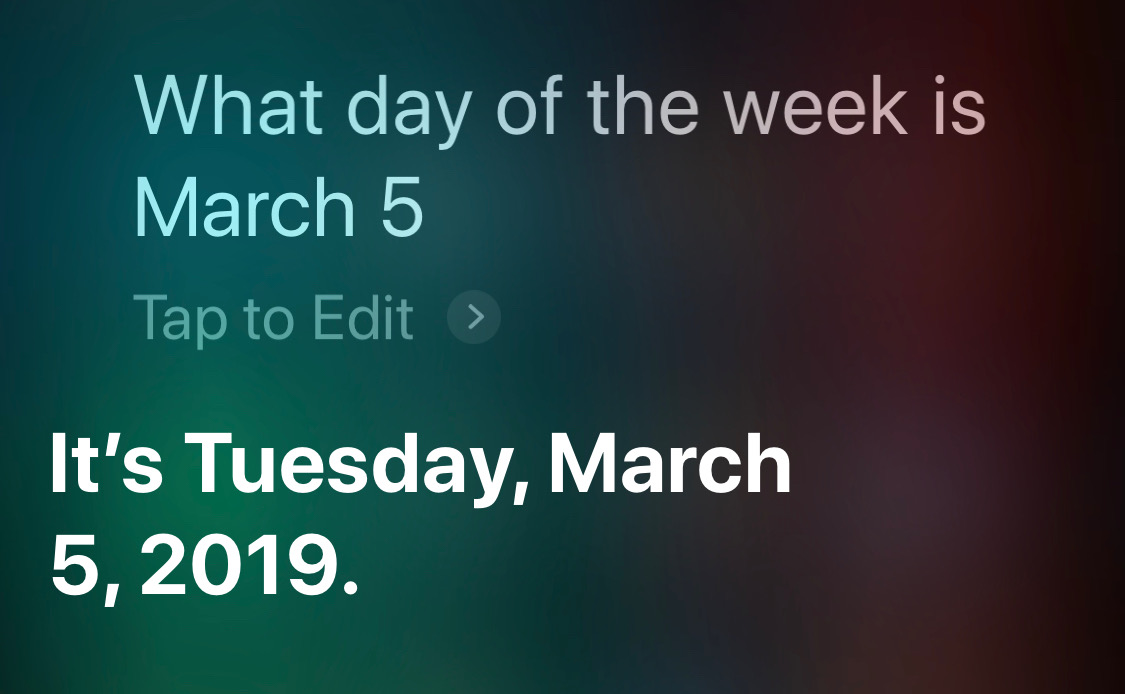
What about a day earlier this year?
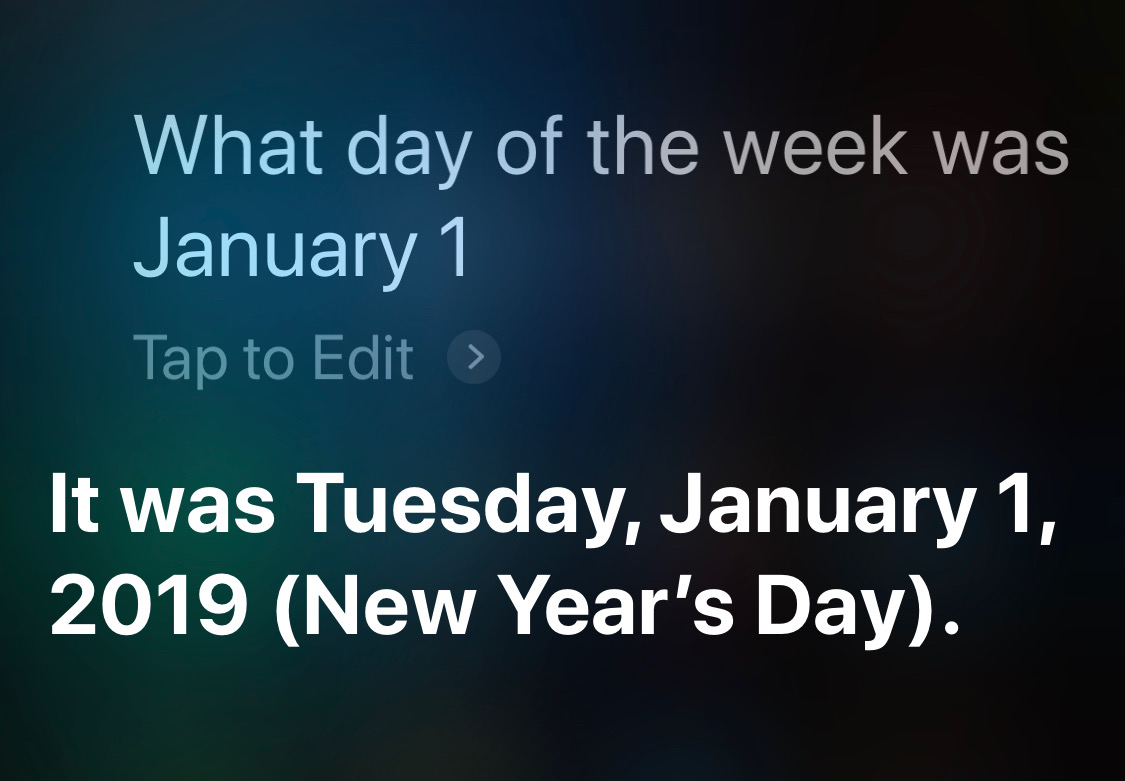
That’s good. But it’ll screw up a date last year, right? Wrong.
And what if I change the tense of the question?
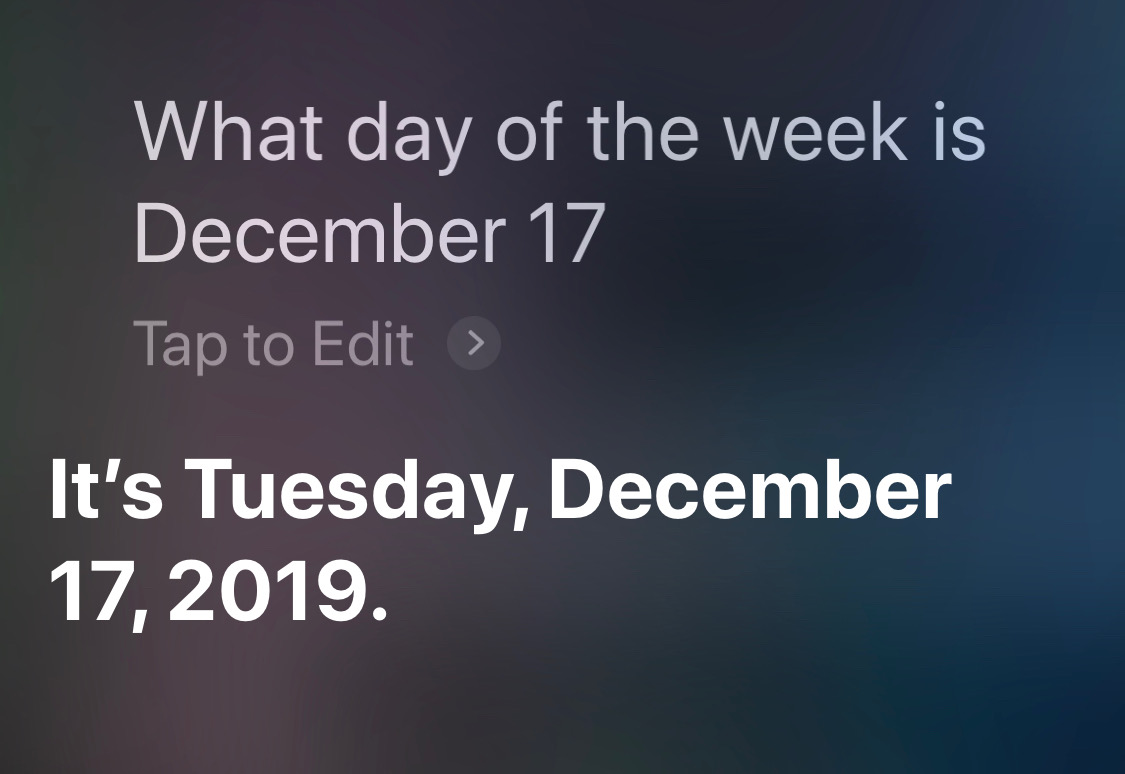
Suddenly, Siri is a master of context. I am at a loss to explain why.
In my experience, Siri is good at figuring out dates some interval away from a given date:
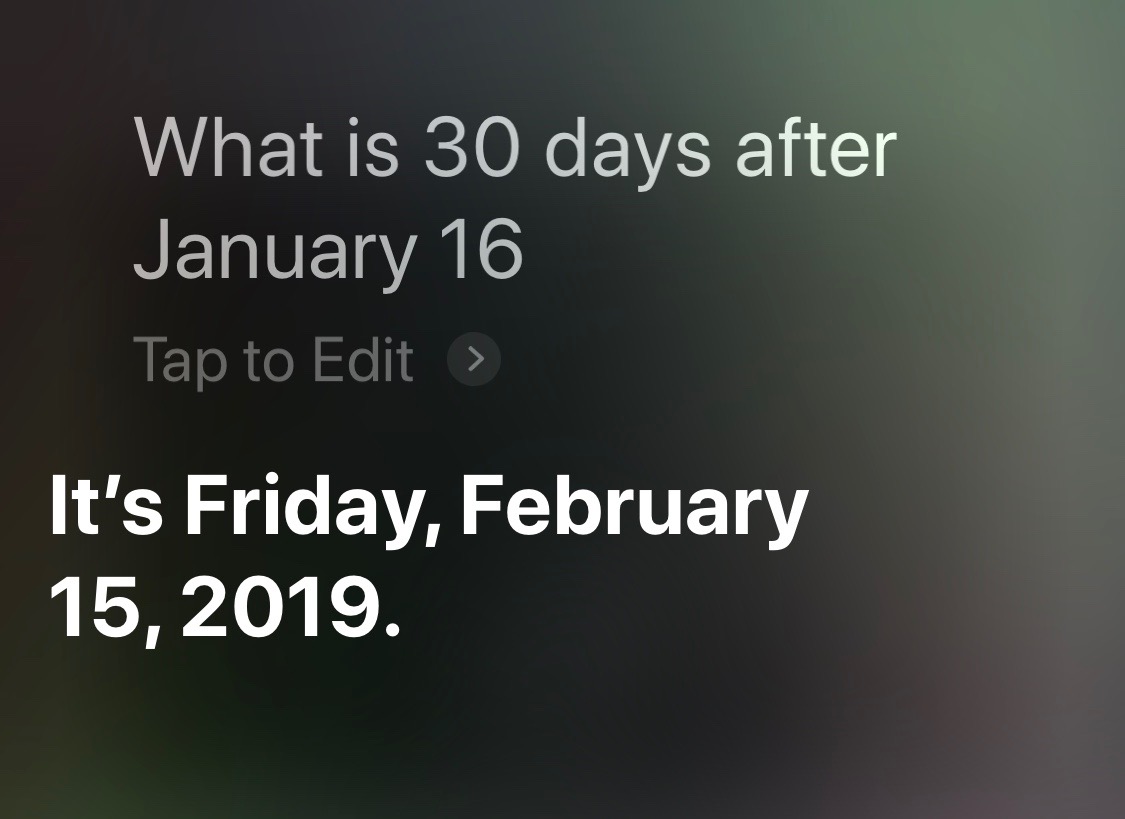
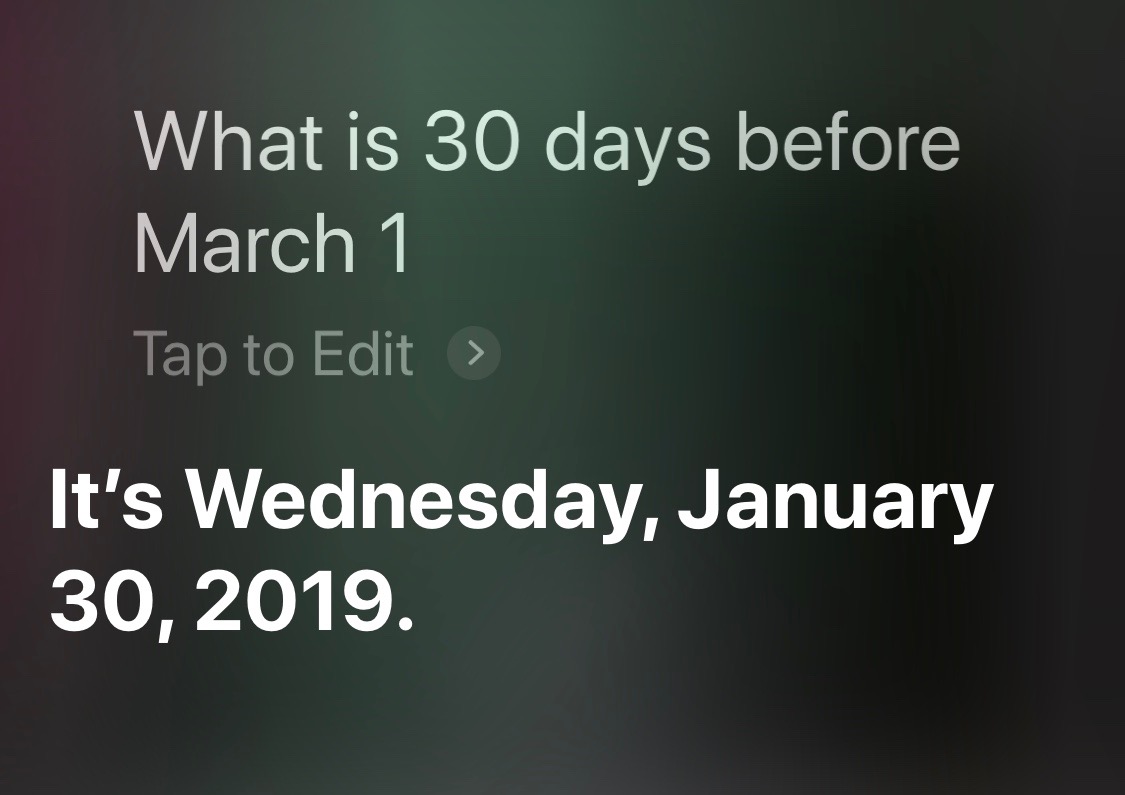
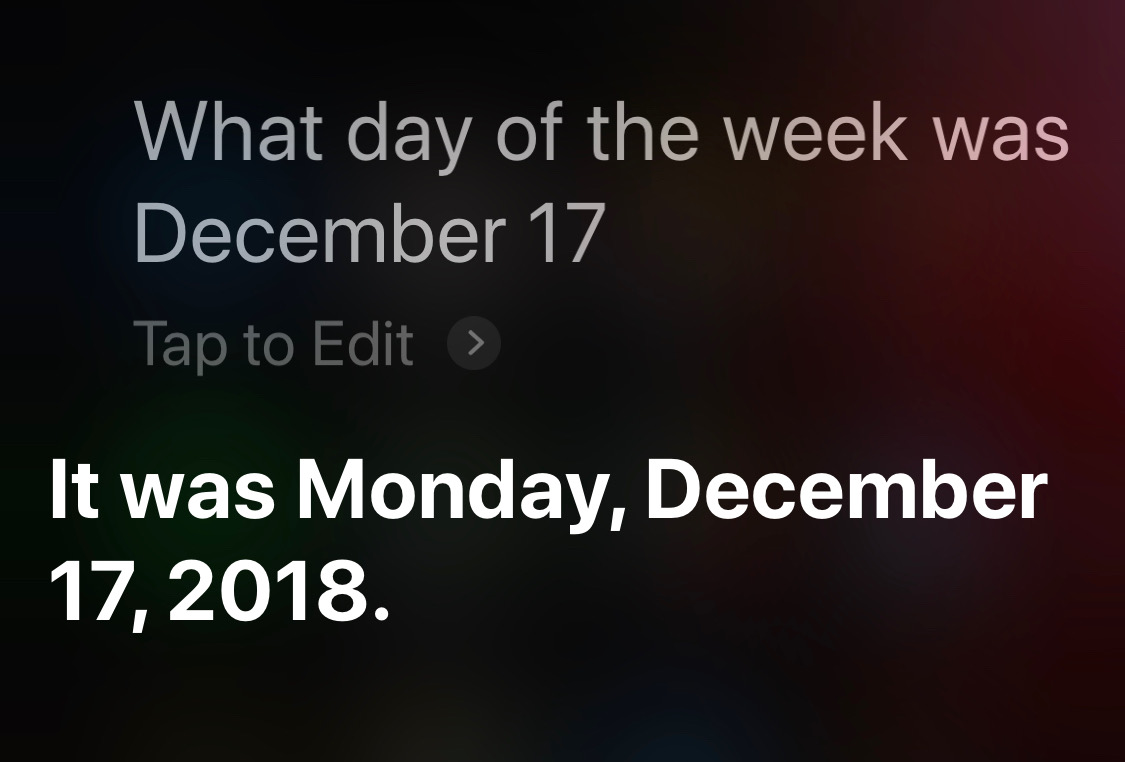
I can’t really blame Siri for thinking I mean this year when I ask about a date after December 17:
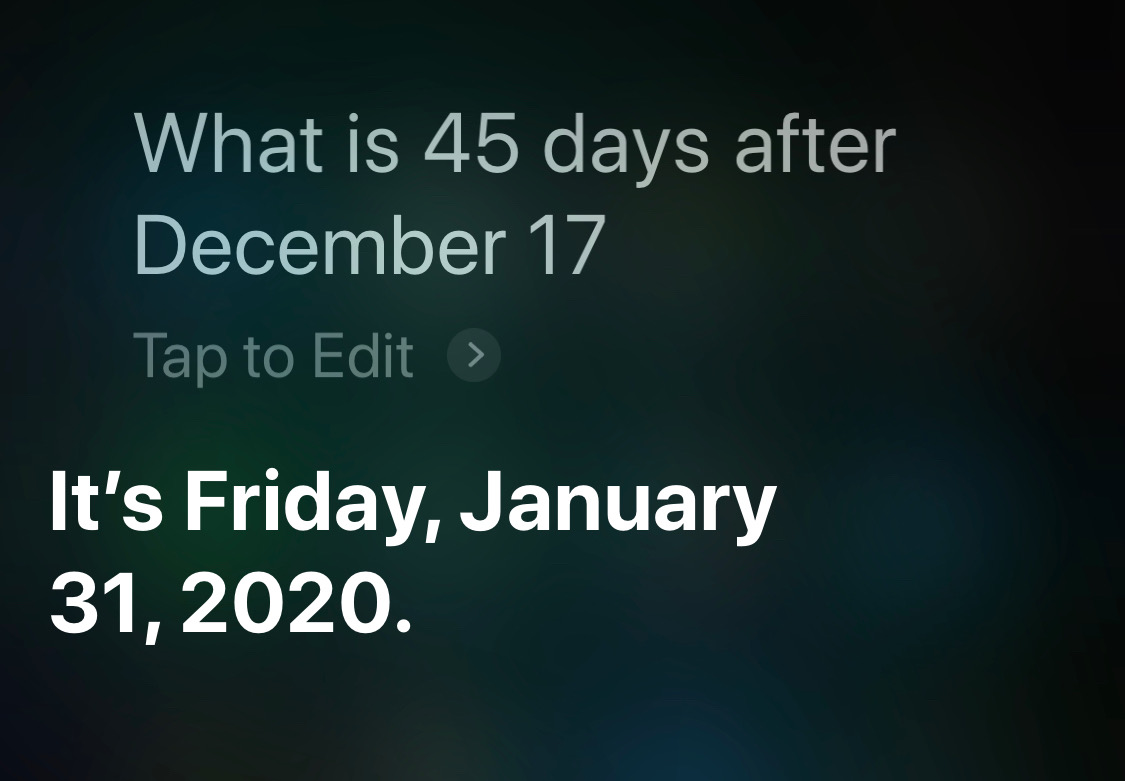
Here’s the question for which Siri has lost some of its intelligence:
Six years ago, Siri answered this kind of question correctly for David Sparks. Interestingly, it gave its answer in the form of a Wolfram Alpha page:
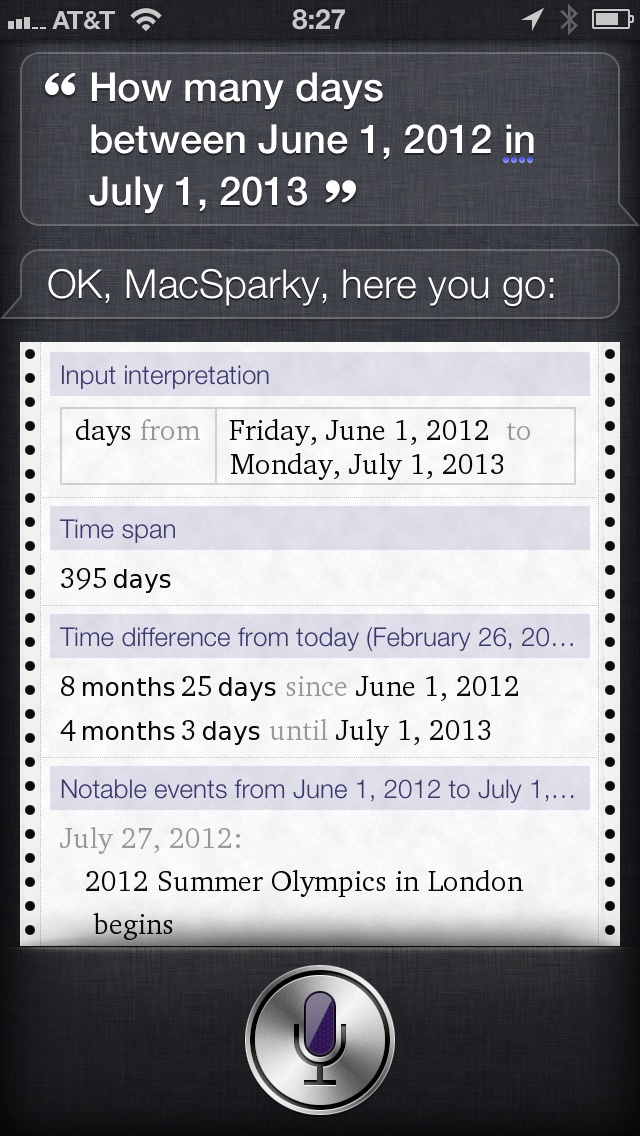
Steve Moser suggested using the “Wolfram Alpha trick” to answer Casey’s question:
@drdrang @caseyliss That is why you use the Wolfram Alpha trick (you’ve probably seen it but just in case).
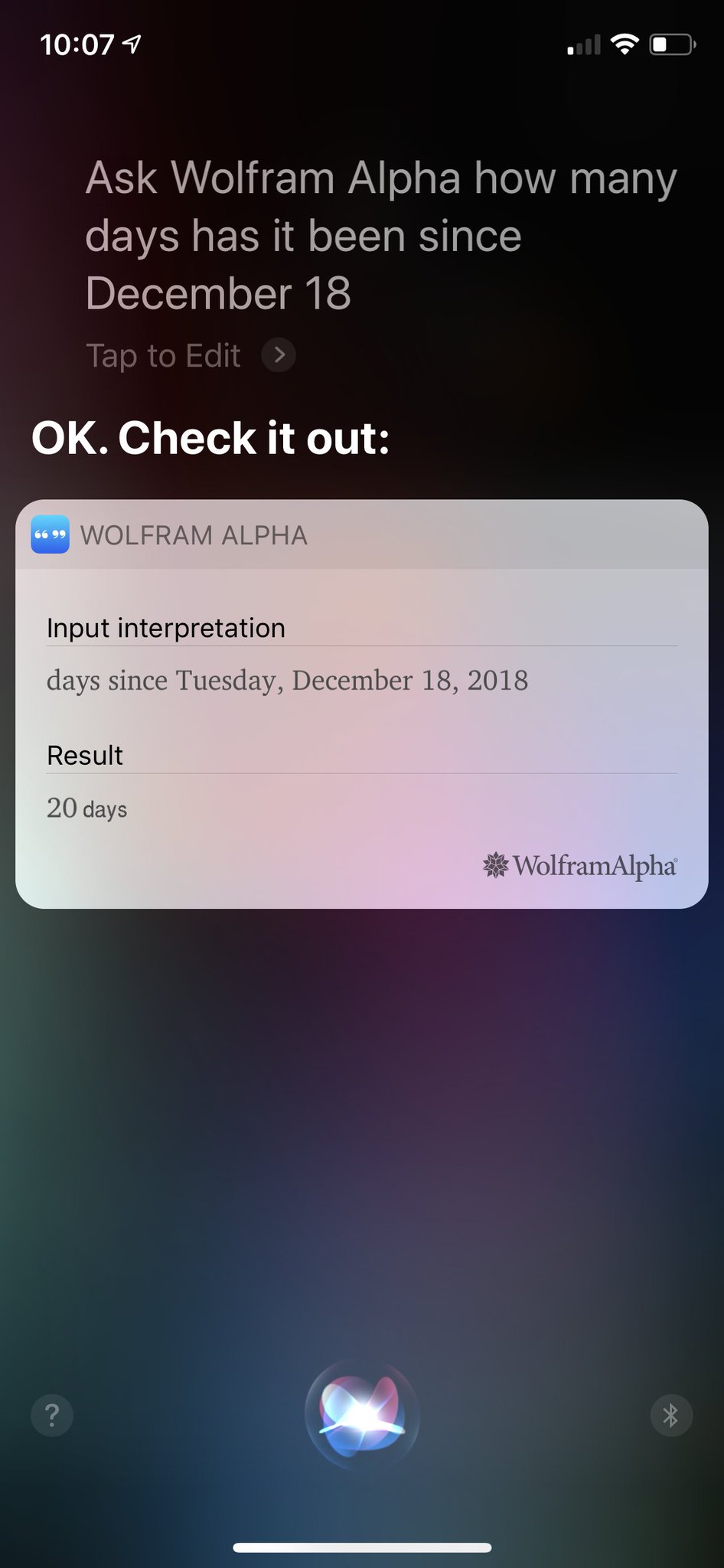
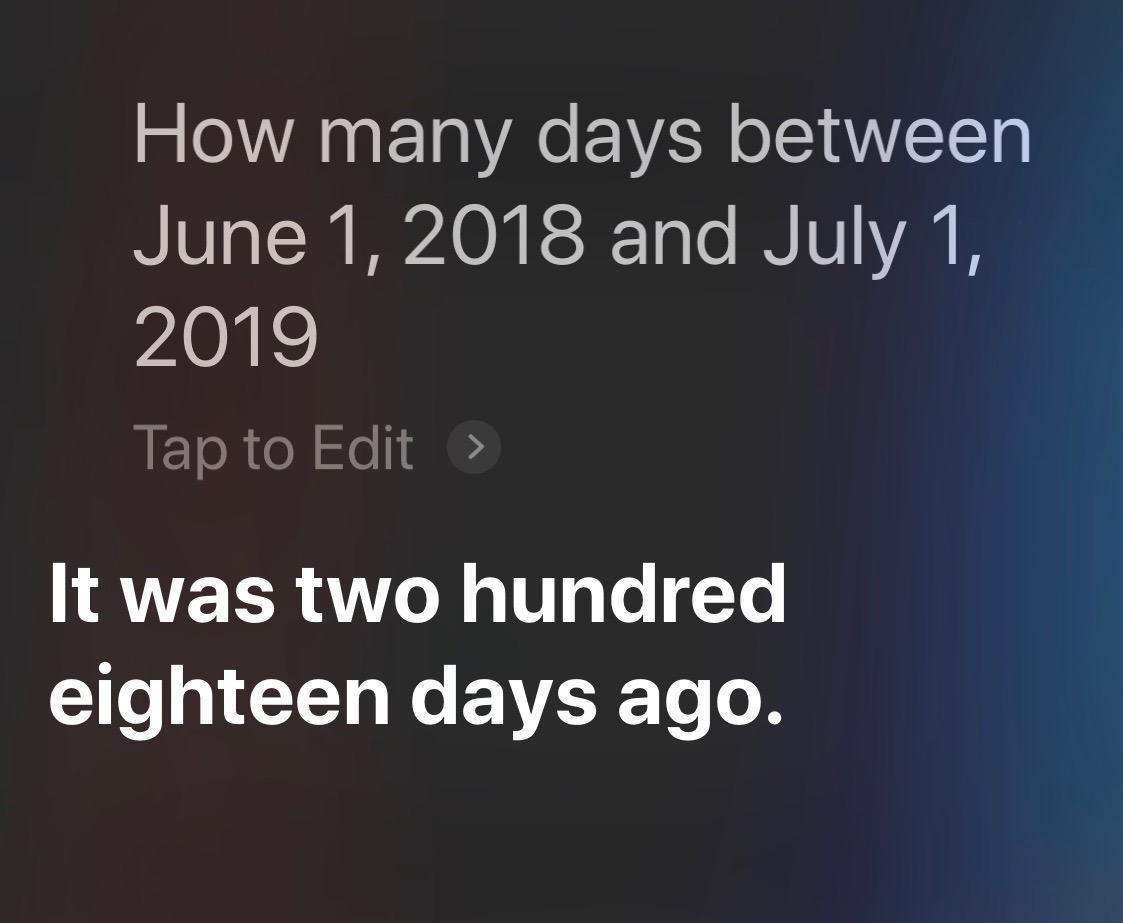
Personally, I think it’s easier to just include the year for that type of question, but the Wolfram Alpha trick is the only way I know of to get the number of days between two dates.
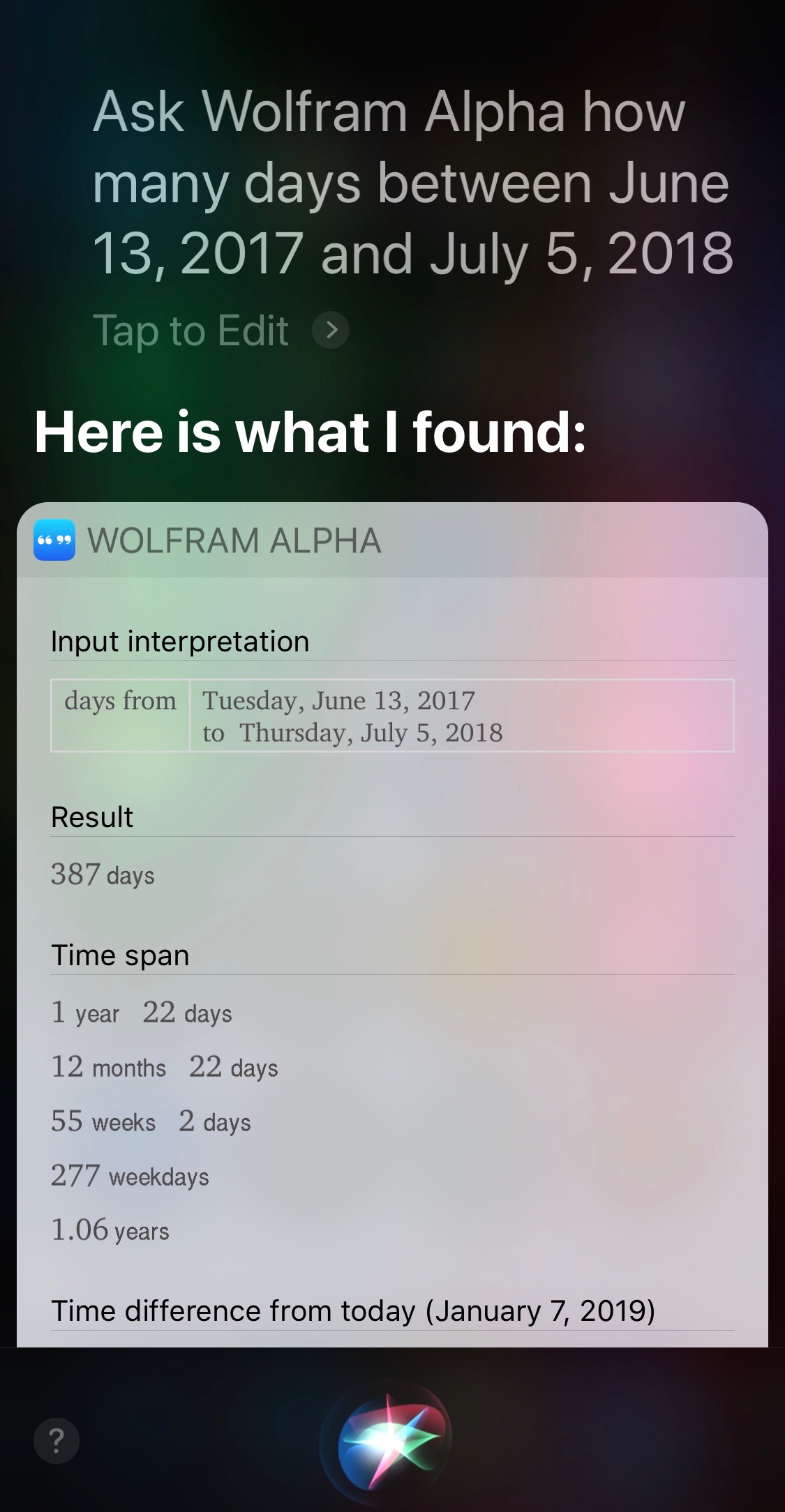
Similarly, Siri can’t give you elapsed time within a day by itself,
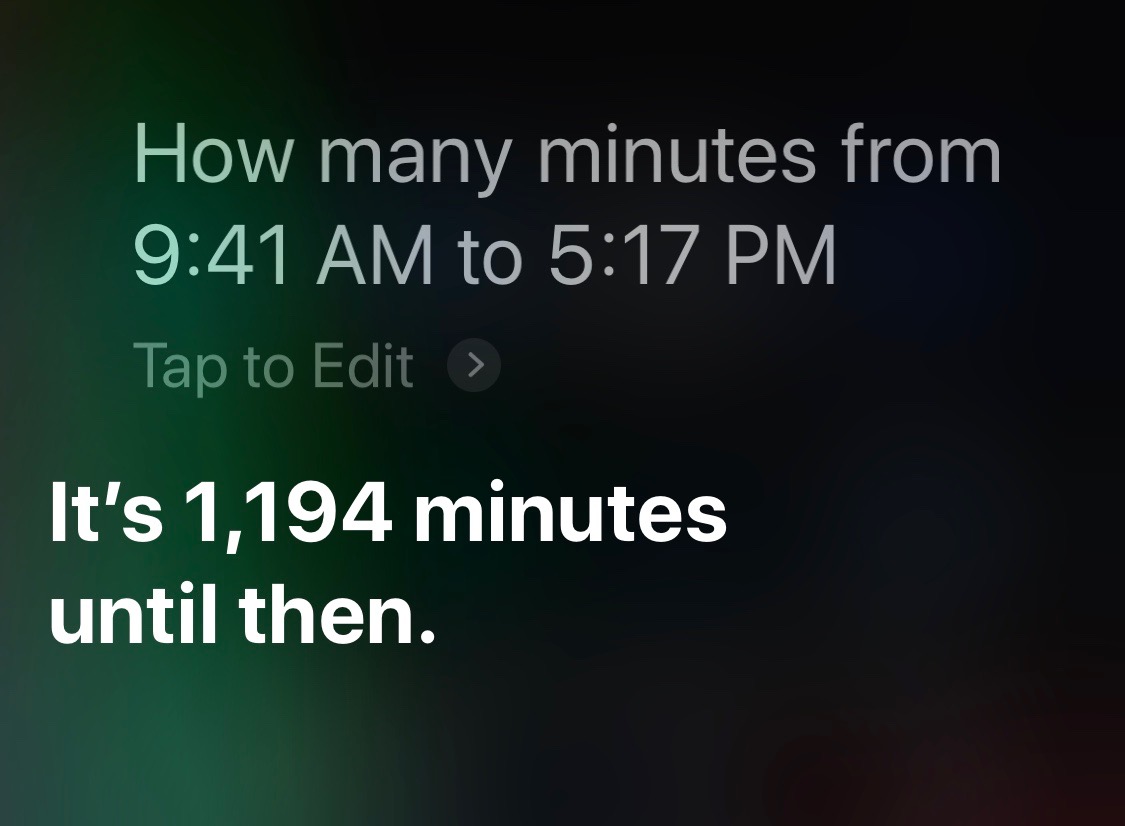
but it can through the Wolfram Alpha trick:
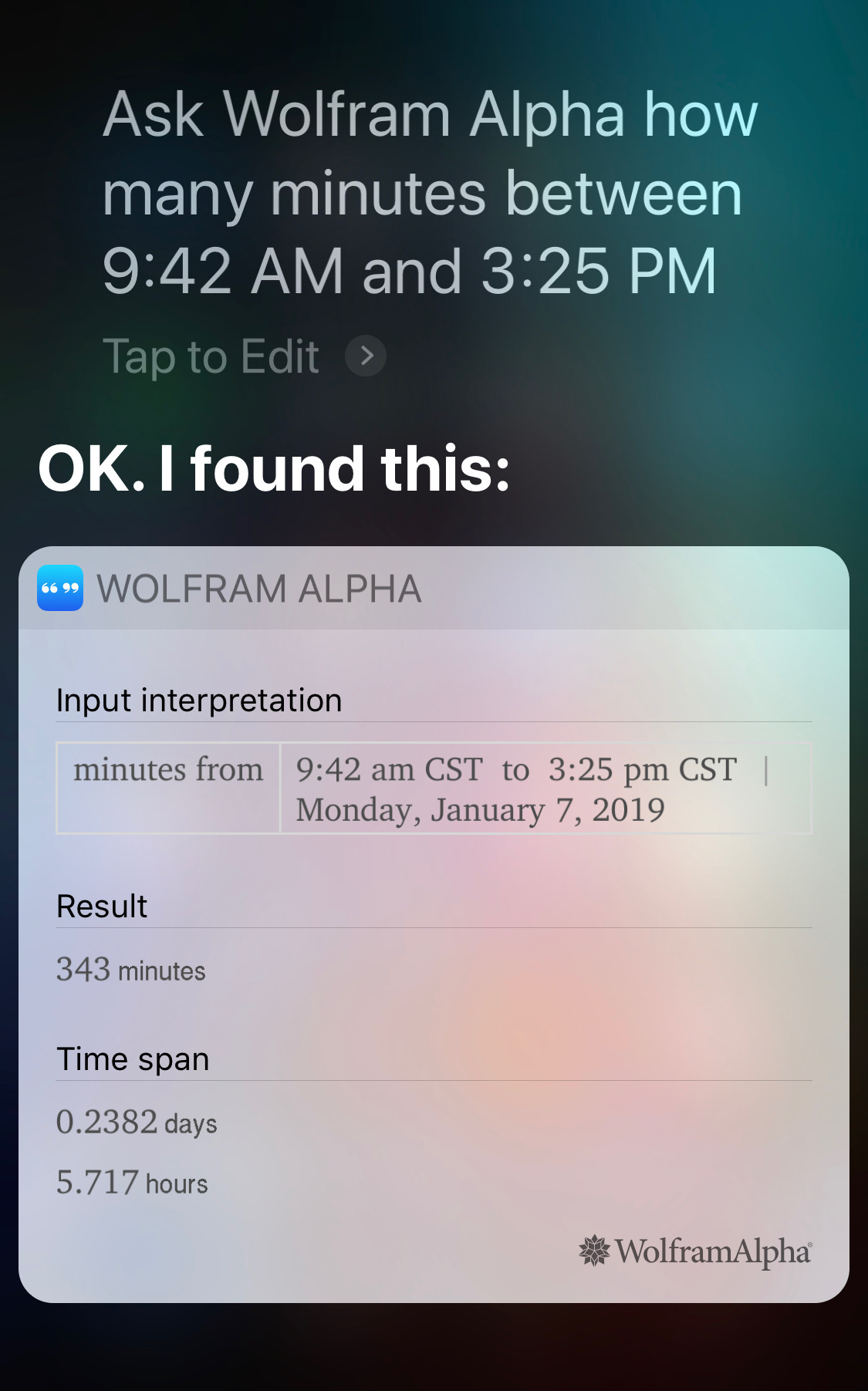
Take care how you phrase this question, or you’ll get the dreaded “here’s what I found on the web” answer:
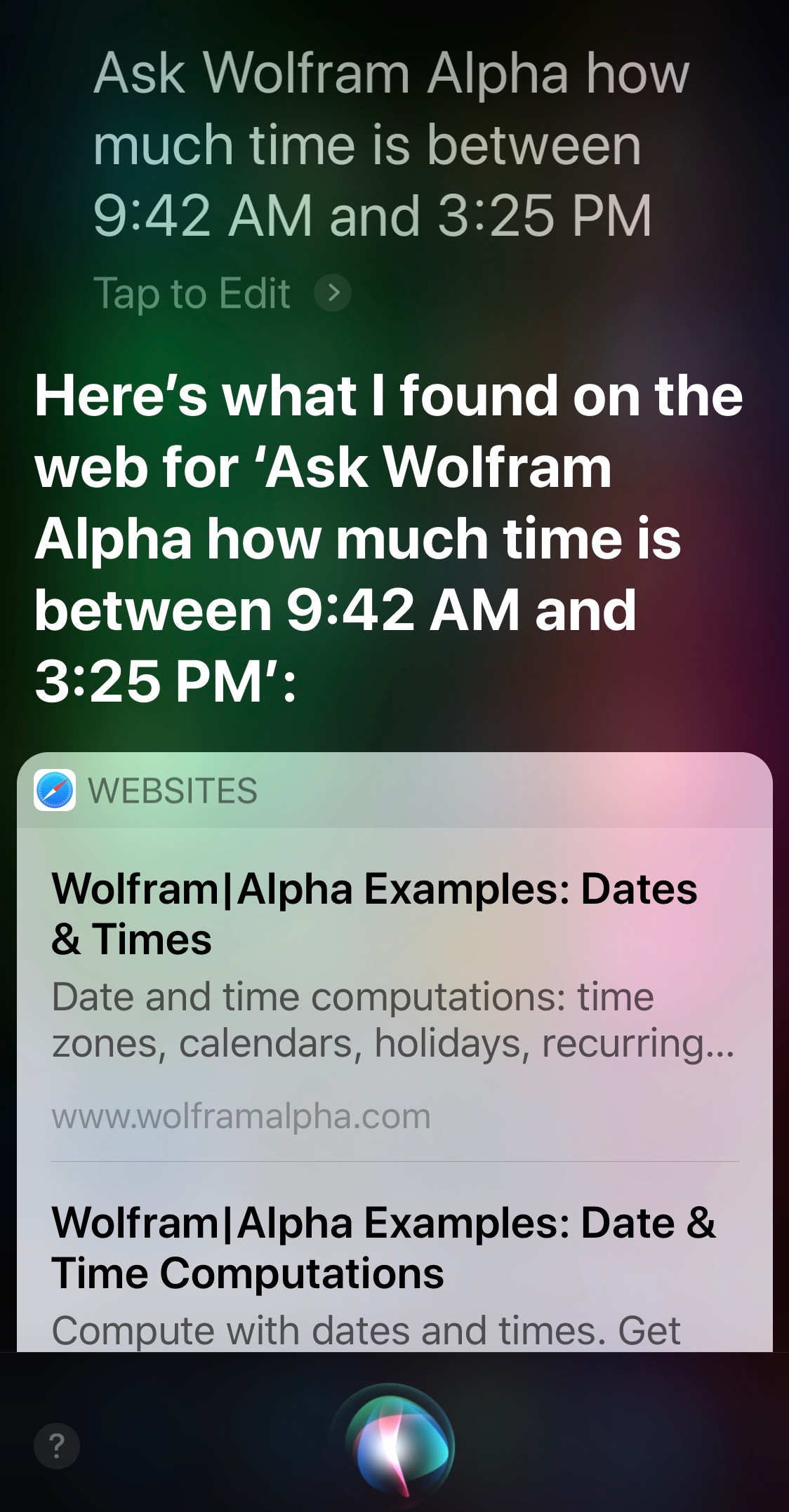
The upshot is that Siri can be good at date and time math, but it needs the right syntax. Not surprising for a computer program, but not how Siri has been promoted by Apple.
Z key followup
January 6, 2019 at 10:43 AM by Dr. Drang
As long as I’m following up on the condition of Apple hardware I’ve broken, I should mention the broken Z key on my Magic Keyboard. This is the keyboard I use with my 9.7″ iPad Pro, and it travels, unprotected, in a narrow compartment of my backpack next to the iPad itself.
Back in the summer, I returned from a business trip and found this damage when I pulled the keyboard out of the backpack:
Well, crap. Anyone know the best way to pop this back on? It’s a recent Magic Keyboard.

I don’t know whether it broke as I slid it into the compartment or as I slid it out, but it obviously caught on something and got pried off.
I ordered a replacement key from LaptopKey.com. It cost about $7.50 with shipping and arrived a few days later. I popped it in place and it worked.
Replazement key zeemz to be working well. Not az zpringy than the original, maybe, but zertainly workable.

(Why did I use the illiterate construction “Not az zpringy than…” instead of “Not az zpringy az…”? Probably because the sentence started life as “Less springy than…”, and I didn’t read it carefully after the rewrite. It’s a fine line between clever and stupid.)
If this weren’t the Z key, I’d be more careful about saying it works. It doesn’t have nearly the snap as the original key and feels distinctly different (worse) than all the other keys. If it were a key I used a lot, I’d be disappointed in its behavior and would have gone hunting for another replacement. But being one of the least-used keys, it’s fine.
I’ve been more careful with the keyboard since then. Eventually, I’l get a Studio Neat Canopy or this less expensive Fintie Carrying Case that Federico Viticci mentioned in his magnum opus on the new iPad Pros.
The springiness of the Magic Keyboard keys, by the way, comes from a rubber dome that holds the key up at rest and undergoes snap-through buckling when you press down on it. Snap-through buckling—with diagrams, equations, and charts—is discussed in my favorite blog post.
AirPod update
January 2, 2019 at 9:13 PM by Dr. Drang
Back in November, I had a little problem with my AirPods:
AirPods (in their case) went through the wash yesterday. At first they worked, but after charging they just make a descending marimba sound when I put them in.New pair now or wait to see if the rumors of an impending release are true?
Because they worked before they needed to be charged, I had some hope that the problem was just with the case and that the earbuds themselves were OK. I made a Genius Bar appointment in early December, had them checked out, and my hopes were fulfilled. Instead of having to shell out $150 for a whole new setup, I walked out of the store with my old earbuds, a new case, and a charge of “only” $70 on my credit card. An expensive mistake on my part, but not as expensive as it could have been.
(A month later, I see that Apple’s lost chance for another $80 of my money has had dire consequences. Sorry, Tim.)
In other AirPod news, my daughter gave me a leather cover for Christmas.

You might not think a case needs a cover, but I do. I keep my AirPods in my right front pocket, along with my keys, a pen, and anything else I need to carry temporarily.1 My old case had picked up stains, and the cover is a good way to keep my new one clean.
The one problem with the cover was that the leather on the back side, which folds over when you flip the top of the case open, was too stiff and would close the top when I took my fingers off it to pull out the pods. The solution was a slight modification of the technique I learned as a kid to break in a new baseball glove: I folded the top of the cover back on itself and held it that way with a rubber band for a day. Worked like a charm.

Comic book database scripts
December 31, 2018 at 4:57 PM by Dr. Drang
As promised in yesterday’s post , this one will detail the scripts and macros I used to build my database of comic books. The focus will be on generating CSV files that can be imported into almost any database system.
Let’s start with what I had: a box with over 500 comics. I hadn’t gone through the box in decades other than to pick out a few issues here and there, but I believed it was mostly sorted in alphabetical order by series title and then numerically by issue number within each series. My plan was to go through the box one series at a time, figure out which issues I had for that series, and use the Grand Comics Database to pull out all the relevant information for each issue.
The key to getting information on a particular issue from the GCD is to know the ID number the GCD has assigned to that issue. That ID is used to construct URLs that access the publication and contents information for the issue. The fastest way to get all the issue IDs for a comic book series is to go to the web page for that series and scrape it.
Here’s an example of a series page, the page for the 1963–1996 run of The Avengers.
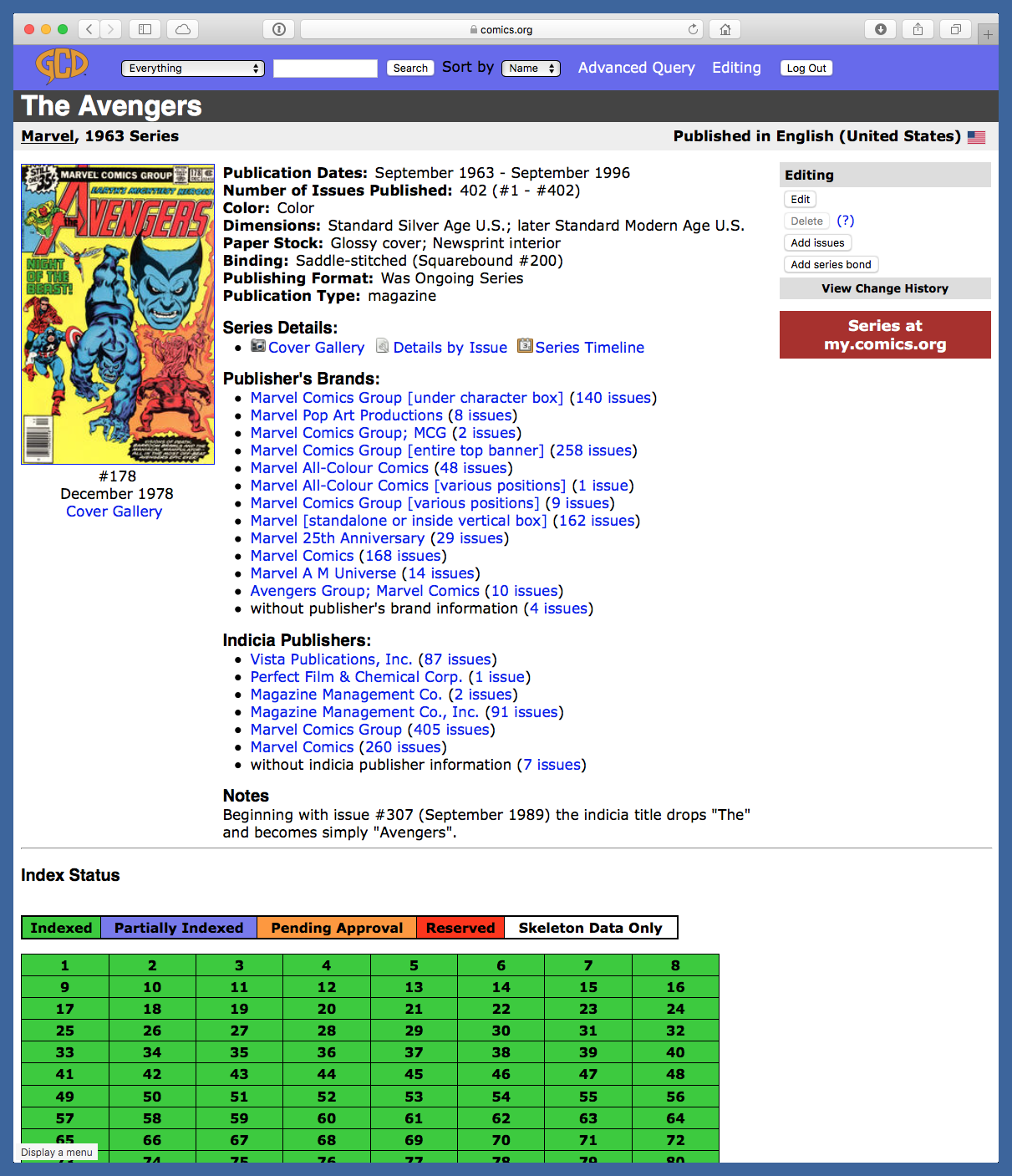
In the Index Status section of the page (the green part in the screenshot) is a table with links to all the individual issues, ordered by issue number.1 The links include within their URLs the issue IDs we want. The goal is to build a list of the issue IDs of every comic book I own and then use that list to collect the information from the GCD to put into my database.
The process for getting all the issue IDs is this:
- Navigate to the page for a series. This has to be done “by hand” using the search features of the GCD website.
Invoke a Keyboard Maestro macro and enter the list of issue numbers I own for that series. Here’s what that looks like:
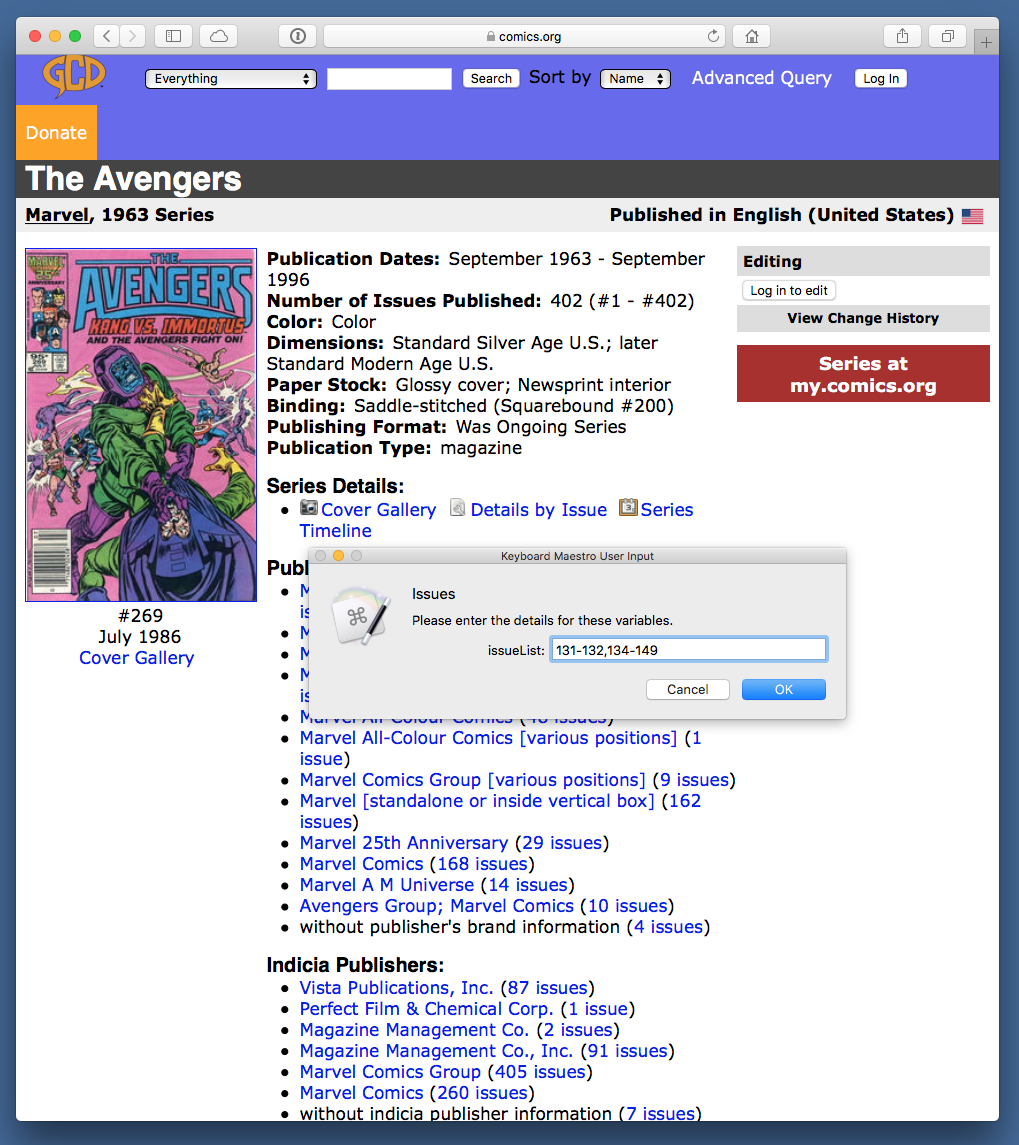
The list is defined by a combination of numbers, commas, and hyphens in the manner you would expect. The macro then scrapes the page, extracts the links for those issues from the Index Status section, and adds a line with the issue ID for each issue to a file named
GCD.csv.- Repeat these steps for every series I own.
The Keyboard Maestro macro invoked in Step 2 is this one:
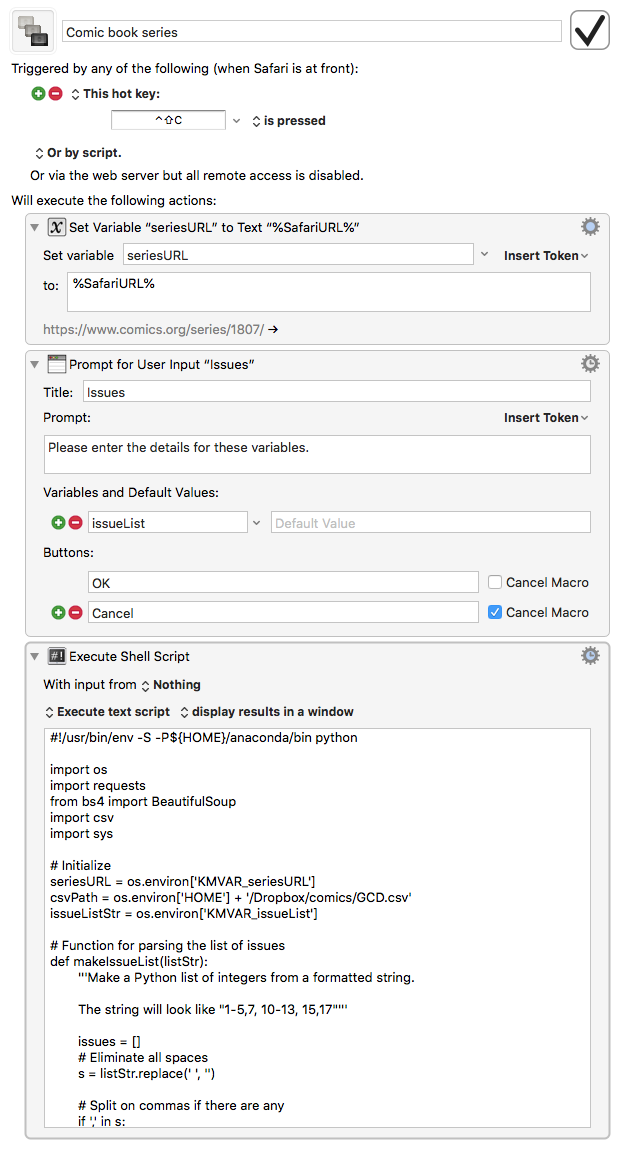
The first two actions define variables, one for the URL of the series page (the current page showing in Safari) and one for the string that defines list of issue numbers. The third action is a Python script that does all the work:
python: 1: #!/usr/bin/env -S -P${HOME}/anaconda/bin python 2: 3: import os 4: import requests 5: from bs4 import BeautifulSoup 6: import csv 7: import sys 8: 9: # Initialize
10: seriesURL = os.environ['KMVAR_seriesURL']
11: csvPath = os.environ['HOME'] + '/Dropbox/comics/GCD.csv'
12: issueListStr = os.environ['KMVAR_issueList']
13: 14: # Function for parsing the list of issues
15: def makeIssueList(listStr):
16: '''Make a Python list of integers from a formatted string.
17: 18: The string will look like "1-5,7, 10-13, 15,17"'''
19: 20: issues = []
21: # Eliminate all spaces
22: s = listStr.replace(' ', '')
23: 24: # Split on commas if there are any
25: if ',' in s:
26: sublists = s.split(',')
27: sublists = [ x.strip() for x in sublists ]
28: else:
29: sublists = [s.strip()]
30: 31: # Loop through sublists
32: for r in sublists:
33: if '-' in r:
34: first, last = [ int(x.strip()) for x in r.split('-') ]
35: issues += range(first, last+1)
36: else:
37: issues.append(int(r.strip()))
38: 39: # Clean up duplicates and sort
40: issues = sorted(list(set(issues)))
41: 42: return issues
43: 44: # Convert the issue list string into a proper Python list
45: issueList = makeIssueList(issueListStr)
46: 47: # Get the page HTML
48: req = requests.get(seriesURL)
49: 50: # Parse the HTML
51: soup = BeautifulSoup(req.text, "html5lib")
52: 53: # Get the series title
54: seriesTitle = soup.title.text.split('::')[-1].strip()
55: 56: # Get the section with the list of issues
57: issueSection = soup.find('div', class_='status_grid')
58: 59: # Create a list of issues. Each item in the list will be
60: # a sublist of seriesTitle, issueNum, issueID
61: issues = []
62: issueTags = issueSection.find_all('div', class_='status_grid_flex')
63: for i in issueTags:
64: if int(i.a.text.split()[0]) in issueList:
65: issueNum = i.a.text
66: issueID = i.a.get('href').split('/')[-2]
67: issues.append([seriesTitle, issueNum, issueID])
68: 69: # Write out the results in CSV format
70: with open(csvPath, 'a') as f:
71: writer = csv.writer(f)
72: writer.writerows(issues)
The weird shebang line at the top is there because I wanted Keyboard Maestro to run the script through the version of Python 3 I installed via Anaconda.
Lines 10 and 12 extract the values from the KM variables defined in the first two steps. Line 11 defines the file where we’re collecting the issue IDs.
Lines 15–42 define the makeIssueList function, which does what it says: takes the string entered in the dialog box from Action 2 of the macro and builds a Python list of integers from it. I think the comments are reasonably good at explaining what it does. One part that is worth noting is Line 40. It converts the list into a set and then back into a list, which might seem stupid, but it’s an easy way to eliminate any duplicates.
The rest of the script is web scraping, aided by the BeautifulSoup library. The series title is in the <title> of the page, before the double colon; Line 54 gets that. The Index Status section, where the table of issue links is, is defined by a <div> with class status_grid, so we extract that portion of the page in Line 57. The table of links is, oddly enough, not an HTML <table>, but a set of <div>s with class status_grid_flex. We collect all of these in Line 62 and then loop through them in Lines 63–67, pulling out the anchor text (which is the issue number) and the portion of the URL that corresponds to the issue ID. When the loop is done, we have a list of lists. Lines 70–72 write those out to the GCD.csv file defined back in Line 11. The Avengers portion of that file looks like this:
The Avengers,131,28139
The Avengers,132,28301
The Avengers,134,28513
The Avengers,135,28606
The Avengers,136,28719
The Avengers,137,28835
The Avengers,138,28941
The Avengers,139,29052
The Avengers,140,29102
The Avengers,141,29262
The Avengers,142,29362
The Avengers,143,29458
The Avengers,144,29543
The Avengers,145,29641
The Avengers,146,29735
The Avengers,147,29828
The Avengers,148,29910
The Avengers,149,30007
Strictly speaking, I don’t really need the series title or issue number, but I put them there to make debugging easier. These scripts don’t just spring out of my head fully formed like Athena from the head of Zeus.
With this macro built, it was time for the no-fun part of the job: pulling all the comics out of their box and going through them to get the issue lists for every series. But a Christmas Miracle occurred. Near the top of the box, hidden between a couple of issues of FOOM was a printed list of everything in the box.

I knew I had made this list in the 80s, but I thought it had been lost when it wasn’t at the top of the box. I can’t remember what software I used to make it, and I have no idea why it was printed using the ImageWriter’s internal font instead of a real Mac font, but there it was. Two copies, even. So instead of having to sort through 500+ comic books, I could just sit down at my iMac and work through this list. It took about an hour or two, much less time than I had been expecting.
With the semi-automated creation of the GCD.csv file out of the way, I could start the fully automated building of the CSV files for issues, covers, and stories. As I mentioned in yesterday’s post, you can download information for a particular issue in CSV form. This FAQ explains how to get the CSV through a link on the issue page. It didn’t take much effort to figure out that the CSV could be downloaded directly using a URL like
<a href="https://www.comics.org/issue/28139/export_issue_csv/" rel="nofollow">https://www.comics.org/issue/28139/export_issue_csv/</a>
where the numeric part in the middle is the issue ID. The first line of the CSV is the information for the issue, and the remaining lines are the information for each “story” in the issue. I put “story” in quotes because the GCD categorizes lots of things that aren’t really stories as “stories”: covers, letters pages, ads, tables of contents—basically everything in an issue that isn’t the issue itself.
The fields for the issue line and the “story” lines are described here, but the description is incomplete. Instead of 17 fields for both issue and “story” records, there are 17 fields for issues and 18 for “stories.” The first 17 fields of “stories” match the documentation, but I could never figure out what the 18th was supposed to be—it was empty in all the records I looked at.
I wanted my database to consist of three tables: issues, covers, and stories, where my definition of a story was limited to stuff inside the comic that most people would think of as a narrative or something related to a narrative. Tables of contents and one-off illustrations were fine, but no ads and no letters pages. I was able to do this filtering (and separate out the covers) by looking at the “Type” field. We’ll see this shortly when we go through the data collection script.
One more thing before we look at the script. The CSV information is available only to registered GCD account holders. The link above won’t work unless you send a cookie with it to indicate you’re logged in to the site. There are probably many ways to figure out the necessary cookie. I logged in using Firefox and used the “Copy as cURL” command from the Network section of its Developer Tools to read all the headers that were sent when I accessed a GCD page. It looked like this:
curl 'https://www.comics.org/series/1571/'
-H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:64.0) Gecko/20100101 Firefox/64.0'
-H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
-H 'Accept-Language: en-US,en;q=0.5'
--compressed
-H 'Referer: <a href="https://www.comics.org/searchNew/?q=avengers'" rel="nofollow">https://www.comics.org/searchNew/?q=avengers'</a>
-H 'Connection: keep-alive'
-H 'Cookie: csrftoken=areallylongstringwithabunchofparts'
-H 'Upgrade-Insecure-Requests: 1'
-H 'Cache-Control: max-age=0'
I copied the Cookie portion into the script to be sent as a header whenever I made a CSV request.
Here’s the Python script that reads the GCD.csv file and writes out the issues.csv, covers.csv, and stories.csv files. It’s named comics.py.
python: 1: import csv 2: import requests 3: import sys 4: 5: # Parameters 6: csvURL = 'https://www.comics.org/issue/{}/export_issue_csv/' 7: imageName = '{}.jpg' 8: cookies = dict(csrftoken='areallylongstringwithabunchofparts') 9: junkWords = 'advertisement promo letters ownership'.split()
10: skeletonCSV = sys.argv[1]
11: issueCSV = 'issues.csv'
12: coverCSV = 'covers.csv'
13: storyCSV = 'stories.csv'
14: issueInputHeaders = '''Number Volume Publisher Brand Publication_Date
15: Date Frequency Price Pages Editor Isbn Notes Barcode On_Sale_Date
16: Issue_Title Reprint_Links Keywords'''.split()
17: issueOutputHeaders = '''ID Title Number Date Price Pages
18: Publisher Frequency Editor Link'''.split()
19: contentInputHeaders = '''Title Type Feature Pages Scripter Penciller Inker
20: Colorist Letterer Editor Genre Characters Job_Number
21: Reprint_Info Synopsis Notes Keywords Other'''.split()
22: coverOutputHeaders = '''ID Title Image ImageName Penciller Inker
23: Colorist Letterer Characters Issue'''.split()
24: storyOutputHeaders = '''ID Title Type Scripter Penciller Inker
25: Colorist Letterer Pages Characters Synopsis Issue'''.split()
26: 27: # Initialize issue and story lists
28: issues = []
29: covers = []
30: stories = []
31: currentIssueID = 0
32: currentCoverID = 0
33: currentStoryID = 0
34: 35: # Open and loop through the skeleton info file
36: with open(skeletonCSV, newline='', encoding='utf-8') as idCSV:
37: idReader = csv.DictReader(idCSV)
38: for book in idReader:
39: # Show progress via series and issue number
40: print('{} #{}'.format(book['series'], book['number']))
41: req = requests.get(csvURL.format(book['id']), cookies=cookies)
42: # req.encoding = 'utf-8'
43: reader = csv.reader(req.text.strip().split('\r\n'))
44: for row in reader:
45: if len(row) == len(issueInputHeaders):
46: currentIssueID += 1
47: issue = dict(zip(issueInputHeaders, row))
48: # Dates have '00' for day; change to '01'
49: # If month is '00', change to blank
50: year, month, day = [ int(x) for x in issue['Date'].split('-') ]
51: if month == 0:
52: issue['Date'] = ''
53: else:
54: day = 1
55: issue['Date'] = '{:02d}/{:02d}/{:4d}'.format(month, day, year)
56: # Get rid of ' USD' from Price
57: issue['Price'] = issue['Price'].replace(' USD', '')
58: # Get rid of floating point part of Pages
59: issue['Pages'] = issue['Pages'].replace('.000', '')
60: issue['Title'] = book['series']
61: issue['ID'] = '{:04d}'.format(currentIssueID)
62: issue['Link'] = 'https://www.comics.org/issue/{}/'.format(book['id'])
63: issues.append({k: issue[k] for k in issueOutputHeaders})
64: else:
65: content = dict(zip(contentInputHeaders, row))
66: if content['Type'] == 'cover':
67: currentCoverID += 1
68: content['ID'] = '{:04d}'.format(currentCoverID)
69: content['Image'] = ''
70: content['ImageName'] = imageName.format(book['id'])
71: content['Issue'] = '{:04d}'.format(currentIssueID)
72: covers.append({k: content[k] for k in coverOutputHeaders})
73: elif any(x in content['Type'] for x in junkWords):
74: continue
75: else:
76: currentStoryID += 1
77: # Get rid of floating point part of Pages
78: content['Pages'] = content['Pages'].replace('.000', '')
79: content['ID'] = '{:04d}'.format(currentStoryID)
80: content['Issue'] = '{:04d}'.format(currentIssueID)
81: stories.append({k: content[k] for k in storyOutputHeaders})
82: 83: with open(issueCSV, 'w', newline='', encoding='utf-8') as f:
84: writer = csv.DictWriter(f, fieldnames=issueOutputHeaders)
85: writer.writeheader()
86: writer.writerows(issues)
87: 88: with open(coverCSV, 'w', newline='', encoding='utf-8') as f:
89: writer = csv.DictWriter(f, fieldnames=coverOutputHeaders)
90: writer.writeheader()
91: writer.writerows(covers)
92: 93: with open(storyCSV, 'w', newline='', encoding='utf-8') as f:
94: writer = csv.DictWriter(f, fieldnames=storyOutputHeaders)
95: writer.writeheader()
96: writer.writerows(stories)
The parameters section in Lines 6–25 defines a bunch of things we’ll use later in the script:
- Templates for the CSV URLs and the cover image files (which we’ll talk about later).
- A dictionary for the GCD cookie discussed above.
- A list of words in the Type field that indicate records I don’t want in my database.
- The input and output files. The input is given as an argument to the script so I could debug it using a smaller input file, one with only 5 lines instead 500.
- The input fields for the issue information and the content (or “story”) information. These came from the documentation discussed above, with an 18th field (“Other”) added for the content.
- The output fields for the issue, cover, and story tables.
Lines 28–30 initialize the lists we’ll use to hold the information as we collect it. Lines 31–33 initialize serial numbers that will be used as the primary keys for our three tables. I could have used the GCD issue ID as the primary key for the issues table but decided to create my own, since that’s what I was doing for the other tables.
Lines 36–37 then opens and parses the input file (GCD.csv) into a list of dictionaries, one for each issue, and Line 38 starts looping through the list. For each issue, Line 40 prints out a progress line to the terminal to let us know where we are, and Line 41 uses requests and the cookie defined in Line 8 to download the CSV. We then look at each line of the CSV and decide what kind of line it is.
We use the length of the dictionary to decide if it’s for an issue or content (Line 45). If it’s for an issue, we
- Generate a new serial number for that issue and add it to the dictionary.
- Put the Date field in
mm/dd/yyyyformat so FileMaker can understand it. GCD saves the date as eitheryyyy-mm-00oryyyy-00-00depending on how much it knows about date. I decided, somewhat arbitrarily, to set the dates with known months to the first of the month. I need a day figure for FileMaker (or any database) to understand that it’s a date, and the first is as good as any. Dates with unknown months (there are only a few of these) are set to blank. I suspect I can fill in the blanks later by looking in the small print at the bottom of the title pages of these issues. - Change the Price to just a floating point number with no “USD” suffix. All of my comic books have prices in US dollars.
- Change the Pages field from floating point to integer. There are no fractional pages.
- Add a link to the GCD page for that issue.
- Add a field for the series title.
- Add the dictionary to the
issueslist, but just the fields we’re interested in, as defined byoutputIssueFields.
If the dictionary is for content, we use its Type field to determine whether its a cover or not (Line 66). If it’s a cover, we
- Generate a new serial number for the cover and add it to the dictionary.
- Add a blank Image field. We’ll fill this later with the cover image.
- Add a field for the name of the cover image file. The image file will be a JPEG named for the issue ID, and we’ll discuss the script that downloads all the cover images when we’re done with this one.
- Add the issue serial number so we can link the tables.
- Add the dictionary to the
coverslist, but just the fields we’re interested in, as defined byoutputCoverFields.
If the dictionary doesn’t have a Type of cover, check to see if it’s stuff I don’t want as defined by the list of junkWords (Line 73) . If not, we’ll consider it a legitimate story and
- Generate a new serial number for the story and add it to the dictionary.
- Change the Pages field from floating point to integer.
- Add the issue serial number so we can link the tables.
- Add the dictionary to the
storieslist, but just the fields we’re interested in, as defined byoutputStoryFields.
When all the comic books have been looped through, Lines 83–96 write out the CSV files for the three tables. These are in a format that can be imported by pretty much any database program. This script, run via
python comics.py GCD.csv
takes from six to eight minutes to complete; the variance, I assume, is due to response time from the GCD.
We’re in the home stretch now. As I mentioned yesterday, artwork is what makes a comic book a comic book, and I couldn’t pass up the opportunity to add cover images to the database. GCD has images at for all of my comics, so I wrote a script, covers.py, to download them. Here it is:
python: 1: import csv 2: import requests 3: from bs4 import BeautifulSoup 4: import sys 5: import shutil 6: 7: # Parameters 8: coverURL = 'https://www.comics.org/issue/{}/cover/4/' 9: cookies = dict(csrftoken='areallylongstringwithabunchofparts')
10: skeletonCSV = sys.argv[1]
11: 12: # Open and loop through the skeleton info file
13: with open(skeletonCSV, newline='', encoding='utf-8') as idCSV:
14: idReader = csv.DictReader(idCSV)
15: for book in idReader:
16: # Show progress via series and issue number
17: print('{} #{}'.format(book['series'], book['number']))
18: 19: # Get the cover page
20: req = requests.get(coverURL.format(book['id']), cookies=cookies)
21: 22: # Parse the HTML
23: soup = BeautifulSoup(req.text, "html5lib")
24: 25: # Get the URL of the cover image
26: imageDiv = soup.find('div', class_='issue_covers')
27: imageURL = imageDiv.find('a', href='/issue/{}/'.format(book['id'])).img['src']
28: img = requests.get(imageURL, stream=True)
29: if img.status_code==200:
30: with open('covers/{}.jpg'.format(book['id']), 'wb') as f:
31: img.raw.decode_content = True
32: shutil.copyfileobj(img.raw, f)
Once again, we’ll use the GCD.csv file as input to get the issue IDs for all my comic books. Line 8 defines a template for the URL of a page with the highest resolution cover image GCD has. We loop through all the issues, get the page with the image via requests and the same cookie we used before, and parse the page with BeautifulSoup.
The image we want is in a <div> of class issue_covers (Line 26). We search that <div> for an anchor with an href attribute that includes our issue ID (Line 27). The URL of the image is in the src attribute of the <img> within that anchor.
Then we fire up requests again to download that image URL (Line 28) and (if the download worked) treat the download as a set of raw bytes and save them to a JPEG file named for the issue ID (Lines 30–32).
After running this script via
python covers.py GCD.csv
which took 15–20 minutes, I had a folder of over 500 JPEGs. The names of the files correspond to the entries in the ImageName field of the Covers table.
Getting the images into the database depends on the database you’re using. For FileMaker, after I had set up all the tables and imported the three CSV files, I wrote this script to loop through the Covers table, read the ImageName field, and insert that image into the Image field.
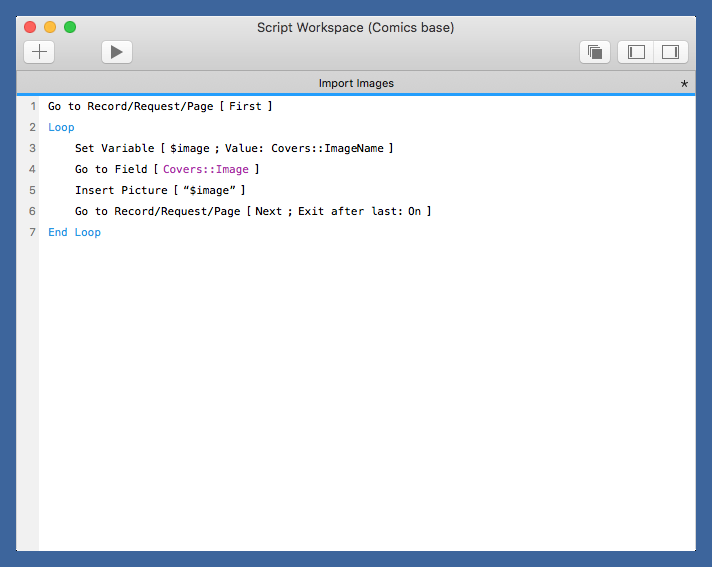
Sorry about the small type size. FileMaker won’t let me change it, perhaps because you don’t actually type FileMaker scripts, perhaps because FileMaker’s programmers are all 25-year-olds who don’t think beyond themselves. Here’s what it says
Go to Record/Request/Page [First]
Loop Set Variable [ $image ; Value: Covers::ImageName ] Go to Field [ Covers::Image ] Insert Picture [ "$image" ] Go to Record/Request/Page [ Next ; Exit after last: On ]
End Loop
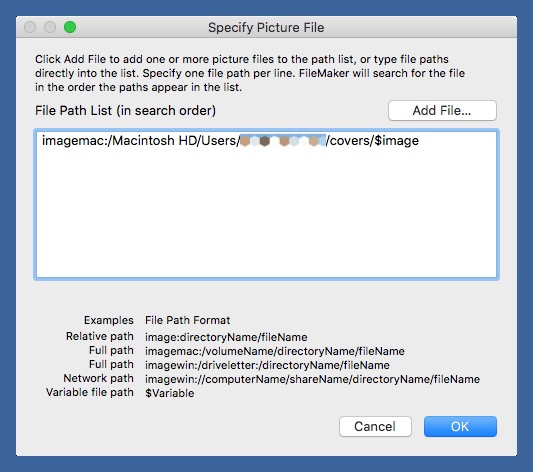
You might be wondering how the script knows where to look for the image files, as there’s no obvious folder name in the script. The full path is hidden in the Insert Picture step. If you click on it, you can bring up the Specify Picture File window, where the full path is written out.
Here’s what an entry in the database looks like in FileMaker Go on my phone.
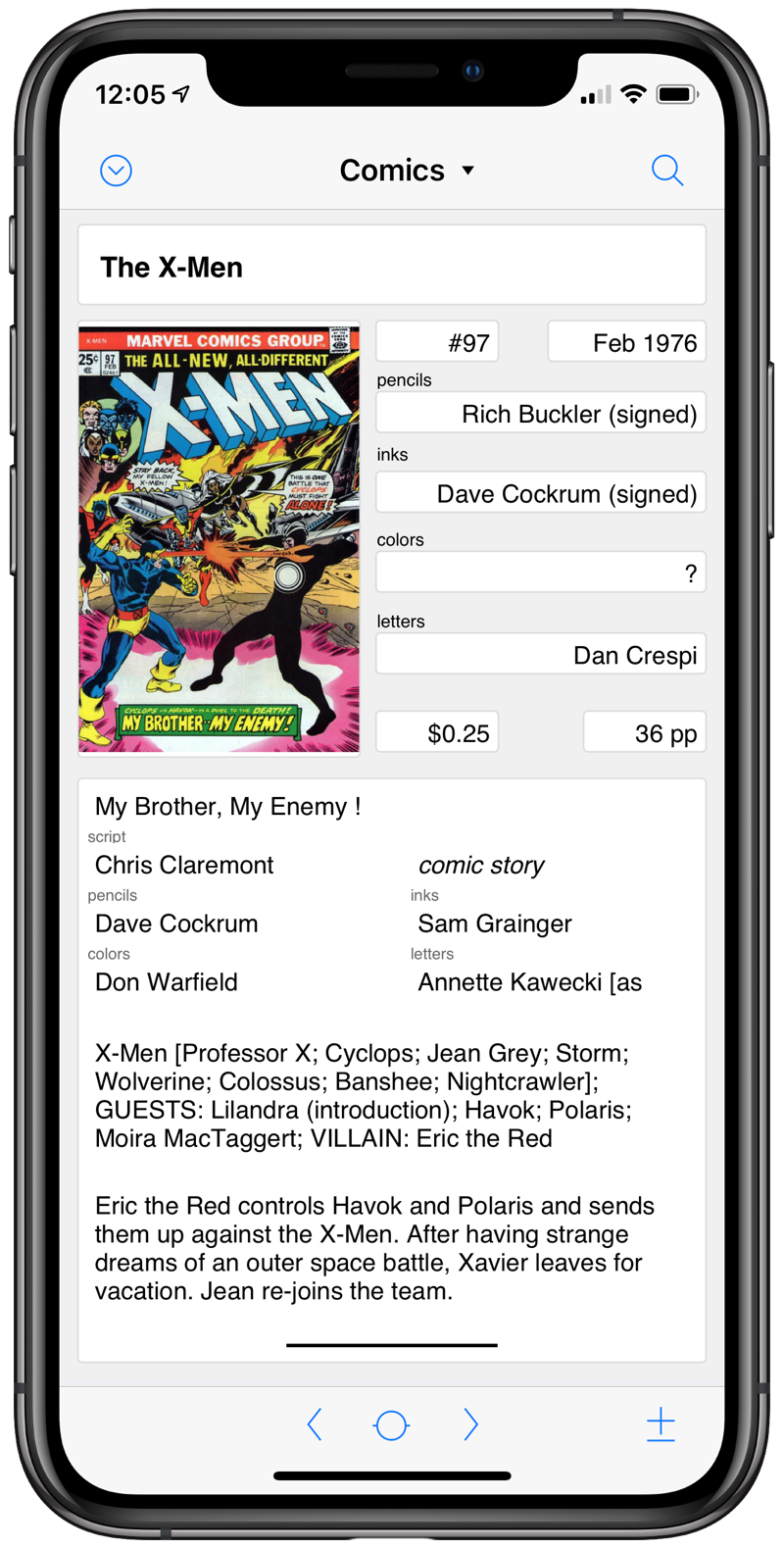
Because the tables are linked, I can show the cover and story information on the page for an issue.
And there you have it. Two years of comics, forty years of neglect, a few days of programming. What will I do with this information now that I have it in my pocket? I can’t tell you, but I know it’s mine.
And now it’s all this